Avoid functions on Indexed column names in WHERE clauses where actual values can be used and when feasible convert Like to IN for better performance
Journeying on to write more scalable and performant queries :)

Problem statement: How can you produce a list of the start times for bookings for tennis courts, for the date '2012-09-21'? Return a list of start time and facility name pairings, ordered by the time.
Exercise source: PgExercise here. One can learn by doing with free SQL dump here
General note: Columns filtered by where clause are usually indexed for better performance(since it’s a recommended good practice to add an index on filter options). The above is an exercise from a sample dump where the starttime column wasn’t initially indexed.
My initial solution:
SELECT
starttime AS start,
name
FROM
cd.bookings
JOIN cd.facilities ON cd.bookings.facid = cd.facilities.facid
WHERE
date(starttime) = '2012-09-21'
AND name LIKE 'Tennis Court%'
ORDER BY
START ASC;Applying Explain, Analyze, Buffers with subsequent results(please note the execution time highlighted in bold):
EXPLAIN (
ANALYZE,
Buffers
)
SELECT
starttime AS start,
name
FROM
cd.bookings
JOIN cd.facilities ON cd.bookings.facid = cd.facilities.facid
WHERE
date(starttime) = '2012-09-21'
AND name LIKE 'Tennis Court%'
ORDER BY
START ASC;Query plan Without an index on date(starttime) ):
Planning Time: 1.874 ms
--------------------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=41.96..41.97 rows=4 width=22) (actual time=0.289..0.292 rows=12 loops=1)
Sort Key: bookings.starttime
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=14
-> Nested Loop (cost=0.28..41.92 rows=4 width=22) (actual time=0.173..0.260 rows=12 loops=1)
Buffers: shared hit=11
-> Seq Scan on facilities (cost=0.00..1.11 rows=2 width=18) (actual time=0.016..0.019 rows=2 loops=1)
Filter: ((name)::text ~~ 'Tennis Court%'::text)
Rows Removed by Filter: 7
Buffers: shared hit=1
-> Index Only Scan using "bookings.facid_starttime" on bookings (cost=0.28..20.38 rows=2 width=12) (actual time=0.103..0.117 rows=6 loops=2)
Index Cond: (facid = facilities.facid)
Filter: (date(starttime) = '2012-09-21'::date)
Rows Removed by Filter: 392
Heap Fetches: 13
Buffers: shared hit=10
Planning:
Buffers: shared hit=317
Planning Time: 1.874 ms
Execution Time: 0.365 ms
(20 rows)Total time: 1.874 + 0.365 = 2.239ms
Query Plan With using a Functional index on date(starttime):
Command used to create functional index:
CREATE INDEX idx_bookings_starttime ON bookings (date(starttime));
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=34.17..34.18 rows=4 width=22) (actual time=0.737..0.740 rows=12 loops=1)
Sort Key: bookings.starttime
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=5
-> Hash Join (cost=5.57..34.13 rows=4 width=22) (actual time=0.692..0.712 rows=12 loops=1)
Hash Cond: (bookings.facid = facilities.facid)
Buffers: shared hit=5
-> Bitmap Heap Scan on bookings (cost=4.44..32.92 rows=20 width=12) (actual time=0.653..0.662 rows=69 loops=1)
Recheck Cond: (date(starttime) = '2012-09-21'::date)
Heap Blocks: exact=2
Buffers: shared hit=4
-> Bitmap Index Scan on idx_bookings_date_starttime (cost=0.00..4.43 rows=20 width=0) (actual time=0.044..0.044 rows=69 loops=1)
Index Cond: (date(starttime) = '2012-09-21'::date)
Buffers: shared hit=2
-> Hash (cost=1.11..1.11 rows=2 width=18) (actual time=0.028..0.029 rows=2 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
Buffers: shared hit=1
-> Seq Scan on facilities (cost=0.00..1.11 rows=2 width=18) (actual time=0.009..0.010 rows=2 loops=1)
Filter: ((name)::text ~~ 'Tennis Court%'::text)
Rows Removed by Filter: 7
Buffers: shared hit=1
Planning:
Buffers: shared hit=20
Planning Time: 1.713 ms
Execution Time: 1.083 ms
(25 rows) Total time: 1.713 + 1.083 = 2.796ms
Proposed solution(which got me curious to check for performance benefits):
EXPLAIN (Analyze, Buffers) select bks.starttime as start, facs.name as name
from
cd.facilities facs
inner join cd.bookings bks
on facs.facid = bks.facid
where
facs.name in ('Tennis Court 2','Tennis Court 1') and
bks.starttime >= '2012-09-21' and
bks.starttime < '2012-09-22'
order by bks.starttime; Query Plan without index
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=11.64..11.68 rows=17 width=22) (actual time=0.149..0.152 rows=12 loops=1)
Sort Key: bks.starttime
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=40
-> Hash Join (cost=1.42..11.29 rows=17 width=22) (actual time=0.075..0.116 rows=12 loops=1)
Hash Cond: (bks.facid = facs.facid)
Buffers: shared hit=37
-> Index Scan using "bookings.starttime" on bookings bks (cost=0.28..9.85 rows=77 width=12) (actual time=0.028..0.055 rows=69 loops=1)
Index Cond: ((starttime >= '2012-09-21 00:00:00'::timestamp without time zone) AND (starttime < '2012-09-22 00:00:00'::timestamp without time zone))
Buffers: shared hit=36
-> Hash (cost=1.11..1.11 rows=2 width=18) (actual time=0.027..0.027 rows=2 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
Buffers: shared hit=1
-> Seq Scan on facilities facs (cost=0.00..1.11 rows=2 width=18) (actual time=0.011..0.014 rows=2 loops=1)
Filter: ((name)::text = ANY ('{"Tennis Court 2","Tennis Court 1"}'::text[]))
Rows Removed by Filter: 7
Buffers: shared hit=1
Planning:
Buffers: shared hit=318
Planning Time: 1.343 ms
Execution Time: 0.194 ms
(21 rows)Total time: 1.343 + 0.194 = 1.537ms
Query Plan with applying the index on the starttime column
To create the index: CREATE INDEX idx_bookings_starttime ON bookings (starttime);
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=11.64..11.68 rows=17 width=22) (actual time=0.137..0.139 rows=12 loops=1)
Sort Key: bks.starttime
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=40
-> Hash Join (cost=1.42..11.29 rows=17 width=22) (actual time=0.078..0.110 rows=12 loops=1)
Hash Cond: (bks.facid = facs.facid)
Buffers: shared hit=37
-> Index Scan using idx_bookings_starttime on bookings bks (cost=0.28..9.85 rows=77 width=12) (actual time=0.024..0.043 rows=69 loops=1)
Index Cond: ((starttime >= '2012-09-21 00:00:00'::timestamp without time zone) AND (starttime < '2012-09-22 00:00:00'::timestamp without time zone))
Buffers: shared hit=36
-> Hash (cost=1.11..1.11 rows=2 width=18) (actual time=0.022..0.023 rows=2 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
Buffers: shared hit=1
-> Seq Scan on facilities facs (cost=0.00..1.11 rows=2 width=18) (actual time=0.016..0.018 rows=2 loops=1)
Filter: ((name)::text = ANY ('{"Tennis Court 2","Tennis Court 1"}'::text[]))
Rows Removed by Filter: 7
Buffers: shared hit=1
Planning:
Buffers: shared hit=359
Planning Time: 2.448 ms
Execution Time: 0.181 ms
(21 rows)
Total time: 2.448 + 0.181 = 2.629ms
If you’d like to deep dive further:
You can find the 69 results and the further filtered 12 row results of the functional index here
You can find the diablo query planner breakdown for both of the indexed queries here & here
Two Key Takeaways comparing both approaches:
Querying with Range for the start time is faster
Case 1 without indexes(Without the starttime index) because it doesn’t have to perform the date operation(which converts something like ‘2012-07-03 11:00:00.000’ to ‘2012-07-03’) before the comparison with ‘2012-09-21’ related actual value.
Case 2 with indexes(i.e., With the normal
starttime index` added and the functional index on(date(starttime))added) because even here in the case of using the functional index it has to create a bitmap of positions using the Bitmap index scan and then it fetches rows using the Bitmap heap scan and whereas in the case of the range query , it goes through the index tree directly to get the relevant data.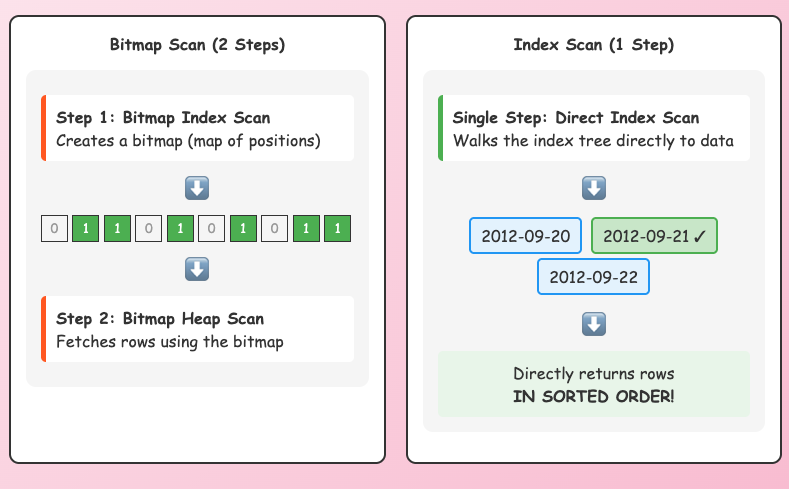
When possible, convert LIKE to IN for speed: IN can use indexes better as it taps into using exactly what one wants. Using like is like saying '“Get me all boxes with labels starting with 'Tennis' “
Lessons Learnt:
IN can use indexes better when compared to LIKE: Proactively look out for when one can convert a Like to IN as it allows one to use indexes better . The current dump for this exercise doesn’t use an index on the name column(probably since it’s mostly a sample data set for learning purposes). Even with perfect indexing, the operation type matters. Direct lookups (IN) beat range scans (LIKE) when you know exactly what you want.
P.S: I’d like to give credits to Yury Lebedev for some feedback on my original blog and introducing me to the concept of functional indexes . This helped me to improve this blog further.